一、内存分配
- 结构体分配内存,内存对齐(8的倍数)
- 对象分配内存,内存对齐(16的倍数)
- 一个NSObject对象占用多少内存?(一个指针变量所占用的大小(64bit,8个字节,32bit,4个字节))
- class_getInstanceSize() 至少需要多少内存
- malloc_size() 实际分配了多少内存
二、对象
-
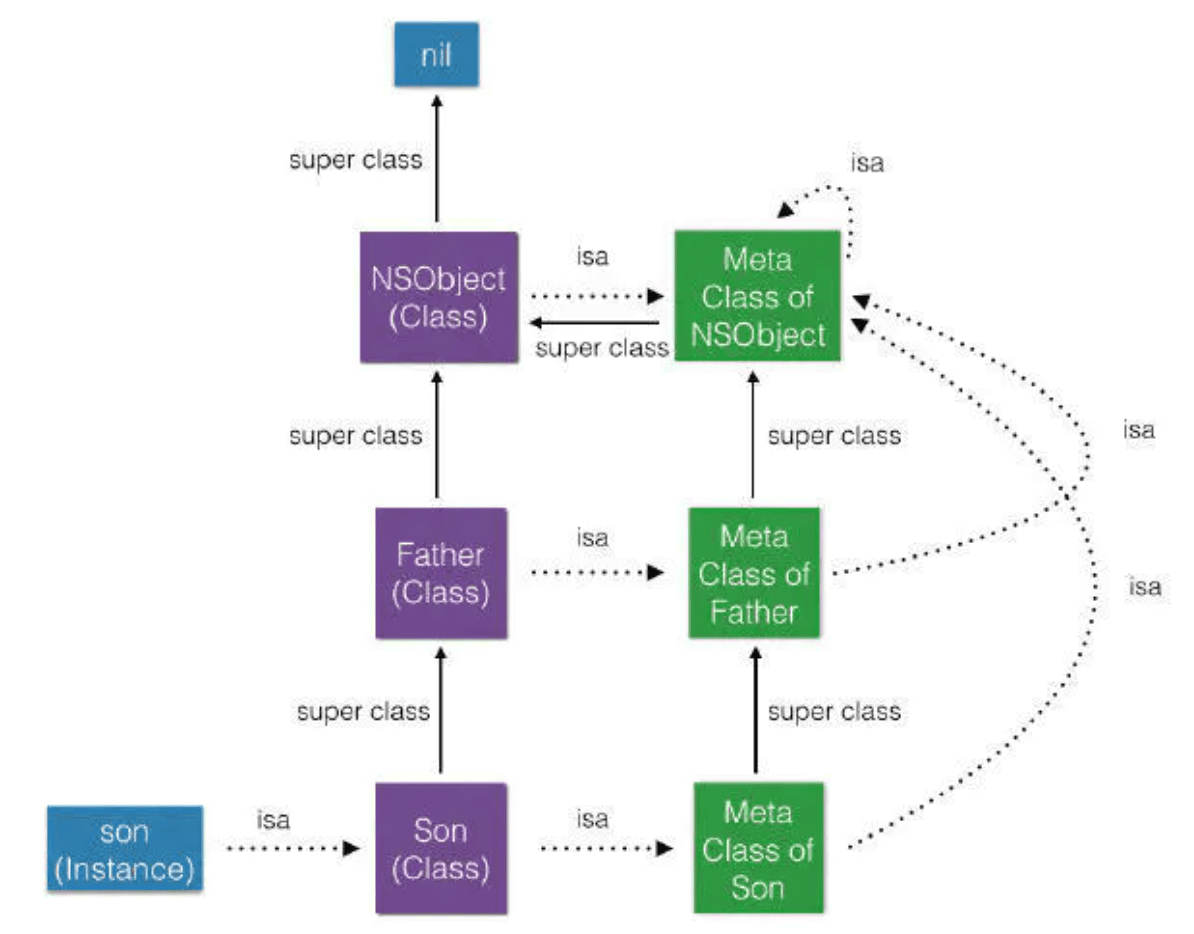
对象类型(实例对象、类对象、元类对象)
-
对象的isa指针指向哪里?(instance对象的isa指向class对象;class对象的isa指向meta-class对象;meta-class对象的isa指向基类的meta-class对象)
-
OC的类信息存放在哪里?(对象方法、属性、成员变量、协议信息,存放在class对象中;类方法存放在meta-class对象中;成员变量的具体值存放在instance对象中)
-
isa & ISA_MASK 才是真正的类对象或元类对象地址(arm64下是0x0000000ffffffff8ULL)
三、KVO、KVC
- KVO的本质(利用runtime动态生成一个子类,重写set方法、class、dealloc、isKVOA方法,并且让instance对象的isa指向这个全新的子类;当修改instance对象的属性时,会调用_NSSetXXXValueAndNotify函数;willChangeValueForKey/setter/didChangeValueForKey)
- 如何手动触发KVO(手动调用willChangeValueForKey/didChangeValueForKey,必须两个方法都调用)
- 直接修改成员变量会触发KVO吗(不会)
- KVC set原理(查找set方法:setKey -> _setKey;查看accessInstanceVariablesDirectly;查找成员变量:_key -> _isKey -> key -> isKey)
- KVC get原理(查找get方法:getKey -> key -> isKey -> _key;查看accessInstanceVariablesDirectly;查找成员变量:_key -> _isKey -> key -> isKey)
四、Category
- Category 原理(编译成struct category_t,存储这对象方法、类方法、属性、协议信息,程序运行时会将Category的数据合并到类信息中)
- Category和Class Extension区别(Class Extension在编译的时候数据就包含在类信息中;Category在运行时才会将数据合并到类信息中)
- +load方法的调用顺序(类:先编译的先调用;先调用父类的 分类:按照编译顺序调用)
- +initialize方法在类第一次接收到消息时调用,先调用父类的+initialize,再调用子类的+initialize
- +load和+initialize最大的区别是,+load通过函数地址直接调用,+initialize通过objc_msgSend进行调用,遵循消息发送的机制(如果分类实现了+initialize,则调用分类的;如果子类没有实现,则调用父类的+initialize;父类的可能被调用多次)
五、关联对象
- key的设置(@selector(key) / static const char key; &key; / static const void *key = &key / @“key")
- 关联对象不是存储在被关联对象本身内存中,而是存储在全局的统一的一个AssociationManager中
- AssciationsManager -> AssociationHashMap -> object: ObjectAssociationMap -> key: ObjectAssociation -> policy/value
- 对象销毁时会把对象对应的ObjectAssociationMap销毁
六、Block
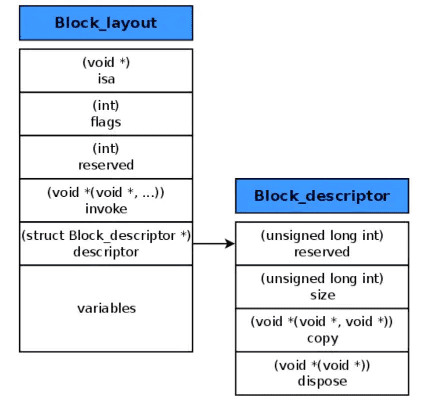
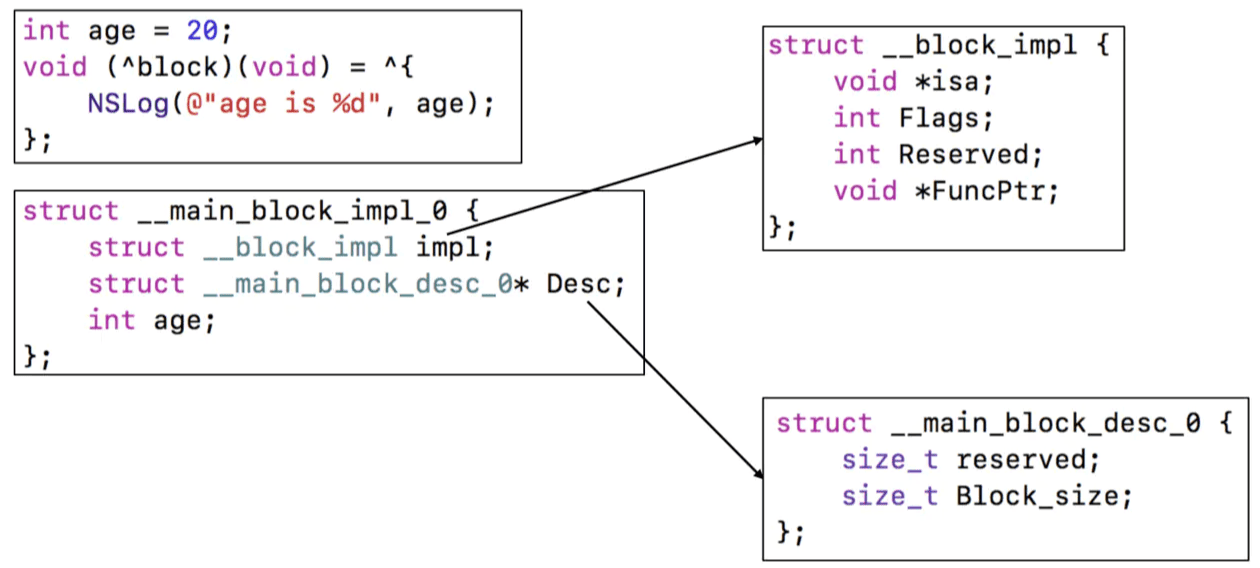
- 本质是结构体对象(__main_block_impl_0)
- block类型(NSGlobalBlock:没有访问auto变量;NSStackBlock:访问了auto变量;NSMallocBlock:NSStackBlock copy)
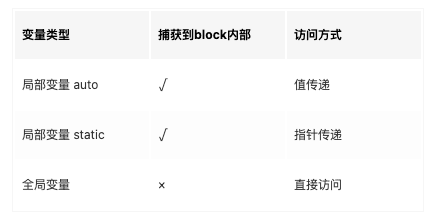
- 捕获auto变量(NSStackBlock:不会强引用auto变量,栈block随时释放,没必要强引用)
- NSMallocBlock:当block拷贝到堆上时,会调用desc里面的copy函数,把auto变量拷贝到堆上;当从堆上移除时,会调用desc里面的dispose函数,release auto变量
- __block 修饰符,会将其修饰的变量包装成一个对象;不能修饰全局变量、静态变量
- MRC下,block不会对__block修饰的对象进行强引用(MRC下,可用__block解决循环引用问题)
- __weak:不会产生强引用,指向的对象销毁时会自动置nil; __unsafe_unretained:不会产生强引用,不安全,指向的对象销毁时,指针存储的地址值不变
七、Runtime
- isa 位域(nonpointer 1为表示优化过的指针;has_assoc 是否有设置过关联对象;has_cxx_dtor 是否有c++的析构函数;shiftcls Class、mata-Class对象的内存地址;magic 对象是否完成初始化;weakly_referenced 是否被弱引用指向过;deallocating 对象是否正在释放;extra_rc 引用计数减1;has_sidetable_rc 引用计数器过大会存储在SideTable中)
- SEL 代表方法、函数名,底层结构跟 char *类似
- 不同类中相同名字的方法,对应的SEL是相同的
- imp 指向函数实现的指针
- Type Encoding “i24@0:8i16f20” 代表:返回值是int,参数总大小为24字节,第一个参数类型是id,从全部参数的第0个字节开始,第二个参数类型是SEL,从全部参数的第8个字节开始,第三个参数类型是int,从全部参数的第16个字节开始,第四个参数类型是float,从全部参数的第24个字节开始
- 方法缓存 cache_t 用散列表缓存曾经调用过的方法,提高方法查找速度(空间换时间)
- 消息发送流程:从cache查找 -> 通过isa指针找到类对象并从class_rw_t里面的方法列表里面查找 -> 从superclass的cache里面查找 -> 从superclass的方法列表里面查找 -> resolveInstanceMathod 尝试动态方法解析一次 -> 重走一次查找方法流程 -> forwardingTargetForSelector 快速消息转发 -> forwardInvocation 完整消息转发(需要先获取方法签名 methodSignatureForSelector)
- NSMethodSignature 方法签名:返回值类型、参数类型
- NSInvocation 封装了一个方法调用,包括:消息接受者、方法名、方法参数
- super:objc_msgSendSuper({self, superclass}, @selector(class)),接收者仍然是子类对象,从父类开始查找方法实现
- runtime用途:关联对象,遍历所有成员变量,字典转模型,自动归档解档,交换方法实现,消息转发机制
- 交换方法时注意类簇,如 NSMutableArray -> __NSArrayM


八、属性
- @dynamic 不要自动生成setter、getter、成员变量
九、RunLoop
- 每条线程都有唯一的与之对应的RunLoop对象
- RunLoop保存在一个全局的字典里,线程作为key,RunLoop作为value
- 线程刚创建时没有RunLoop对象,RunLoop会在第一次获取它时创建
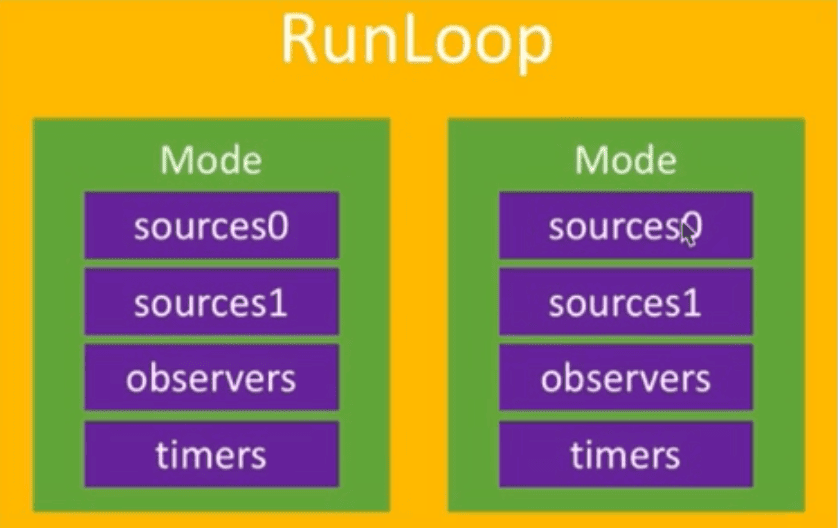
- 一个RunLoop包含若干个Mode,RunLoop启动时只能选择其中一个Mode作为currentMode,如果需要切换Mode,只能重启RunLoop
- 如果Mode里面没有任何Sources0/Source1/Timer/Observer,RunLoop会立马退出
- Source0: 触摸事件/performSelector:onThread:
- Source1: 基于Port的进程间通信/系统事件捕捉
- Timers: NSTimer/performSelector:withObject:afterDelay:
- Observers: 监听RunLoop状态/UI刷新/AutoreleasePool(BeforeWaiting)
- 作用:保持程序持续运行、处理各种事件、节省cpu资源
- GCD不依赖RunLoop,但是异步到主线程则会唤醒RunLoop
- RunLoop响应用户操作:Source1接收事件,交给Source0处理
- RunLoop应用:线程保活/卡顿监控/Timer滑动时停止/性能优化
- defaultMode和trackingMode都是真实存在的模式,commonMode时一个标记
- [NSRunLoop run] 相当于不停调用 [NSRunLoop runMode:beforeDate:]
- 子线程默认没有RunLoop,子线程中调用[performSelector:withObject:afterDelay:]无效

十、多线程
- 同步:在当前线程中执行任务,不具备开启新线程的能力;
- 异步:在新的线程中执行任务,具备开启新线程的能力;
- 并发:多个任务并发执行;
- 串行:一个任务执行完毕后,再执行下一个任务;
- 使用sync往当前串行队列中添加任务,会产生死锁;
- OSSpinLock:自旋锁,等待锁的线程会处于忙等状态,一直占用CPU资源;优先级反转;如果等待锁的线程优先级较高,它会一直占用着CPU资源,优先级低的线程就无法释放锁;
- 递归锁:允许同一个线程对一把锁重复加锁
- atomic,相当于在getter、setter内部加了锁,并不能保证使用属性的过程是线程安全的
- 多读单写:pthread_rwlock dispatch_barrier_async
- 通过dispatch_barrier_async实现多读单写,传入的并发队列必须时通过dispatch_queue_create创建的
十一、Timer
- NSTimer:内存泄漏问题,不准时问题
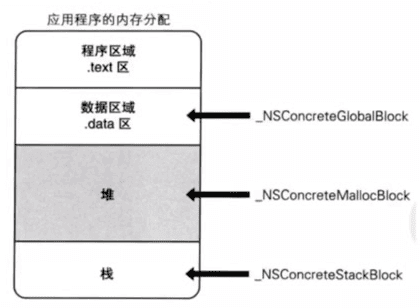
十二、内存布局
- 从低地址到高地址:保留 -> 代码段 -> 数据段(字符串常量 -> 已初始化数据 -> 未初始化数据) -> 堆 -> 栈 -> 内核区
- TaggedPointer:Tag + Data,将数据直接存储到指针中;当指针不够存储数据时,才会使用动态分配内存的方式来存储数据
- 如何判断TaggedPointer:macOS:最低有效位为1;iOS:最高有效位为1
- 堆空间中对象的内存地址最后一位是0,因为结构体有内存对齐,16的倍数
- 引用计数:新创建的对象引用计数为1,当引用计数为0时对象会被销毁
- synthesize:生成成员变量和属性的setter、getter
- alloc/new/copy/mutableCopy 返回了一个对象,需要调用release或者autorelease
- copy:不可变拷贝,产生不可变副本
- mutableCopy:可变拷贝,产生可变副本
- 深拷贝:内容拷贝,产生新的对象
- 浅拷贝:指针拷贝,没有产生新的对象
- 自定义对象实现copy:遵守NSCopying协议,并实现-copyWithZone方法
- 引用计数的存储:64bits中,引用计数可以存储在isa指针中,如果不够存储,则会存储在SideTable中
- AutoreleasePoolPage:每个对象占用4096个字节,存放内部成员变量和autorelease对象的地址
- AutoreleasePoolPage通过双向链表的形式连接在一起
- autorelease与runloop的关系:entry -> push; beforeWaiting -> pop -> push(runloop休眠之前); exit -> pop
十三、CPU卡顿优化
- 尽量使用轻量级的对象,如CALayer代替UIView
- 不要频繁修改UIView的frame、bounds、trasform等属性
- 提前计算好布局,有需要时一次性修改,避免多次修改
- Autolayout会比直接设置frame消耗更多CPU资源
- 图片的size最好跟UIImageView的size保持一致
- 控制线程的最大并发数
- 把耗时操作放在子线程(文本处理(尺寸计算、绘制)、图片处理(解码、绘制))
十四、GPU卡顿优化
- 避免短时间内大量图片的显示,尽可能将多张图片合成一张进行显示
- GPU能处理的最大纹理尺寸是409684096,超过这个尺寸会占用CPU资源进行处理
- 尽量减少视图数量和层次
- 减少透明的视图
- 避免出现离屏渲染
- 离屏喧嚷需要创建新的缓冲区,需要多次切换上下文环境
- 触发离屏渲染:光栅化(layer.shouldRasterize = YES);遮罩(layer.mask);圆角(同时设置 layer.masksToBounds = YES、layer.cornerRadius > 0)
十五、耗电优化
- 尽可能降低CPU、GPU功耗
- 少用定时器
- 优化IO操作(避免频繁写入小数据,批量写入;使用dispatch_io操作文件;数据量比较大时使用数据库)
- 网络优化(压缩网络数据;使用缓存;使用断点续传;用户可取消未响应请求;批量传输)
十六、App的加载
- 装载App的可执行文件,递归加载所有依赖的动态库
- 调用map_images进行可执行文件内容的解析和处理
- 在load_images中调用call_load_methods,调用所有Class和Category的+load方法
- 进行各种objc结构的初始化(注册Objc类,初始化类对象等等)
- 调用C++静态初始化器和__attribute__((constructor))修饰的函数
十七、启动优化
- 减少动态库
- 减少Objc类、分类、Selector数量
- 减少C++虚函数数量
- Swift尽量使用struct
- +initialize和dispatch_once取代__attribute__((constructor))、C++静态构造器、Objc的+load